| Version 3 (modified by , 7 years ago) ( diff ) |
|---|
Animated movie of neuroscience brain data with ParaView
Background
At FZJ, the institute for structural and functional organisation of the brain (INM-1) develops a 3-D model of the human brain which considers cortical architecture, connectivity, genetics and function. The INM-1 research group Fiber Architecture develops techniques to reconstruct the three-dimensional nerve fiber architecture in mouse, rat, monkey, and human brains at microscopic resolution. As a key technology, the neuroimaging technique Three-dimensional Polarized Light Imaging (3D-PLI) is used. To determine the spatial orientations of the nerve fibers, a fixated and frozen postmortem brain is cut with a cryotome into histological sections (≤ 70 µm). Every slice is then scanned by high resolution microscopes.
The datset used in this visualisation scenario consists of 234 slices of gridsize 31076x28721 each, resulting in a rectilinear uniform grid of size 31076x28721x234 (~200 GB memory usage in total). The data was stored as raw binary unsigned char data, one file for each slice.
Conversion to HDF5
Because ParaView has a very usable XDMF/HDF5 reader, we decided to convert the raw data to hdf5 first. This was done using a Python script. Before Python can be used on our JURECA cluster, the necessary modules have to be loaded first:
module load GCC/5.4.0 module load ParaStationMPI/5.1.5-1 module load h5py/2.6.0-Python-2.7.12 module load HDF5/1.8.17
In the Python-script, the directory containing the 234 slice files is scanned for the names of the raw-files. Every file is opened and the raw content is read into a numpy array. This numpy array is written into a hdf5 file, which was created first.
import sys
import h5py # http://www.h5py.org/
import numpy as np
import glob
dir = "/homeb/zam/zilken/JURECA/projekte/hdf5_inm_converter/Vervet_Sehrinde_rightHem_direction/data"
hdf5Filename="/homeb/zam/zilken/JURECA/projekte/hdf5_inm_converter/Vervet_Sehrinde_rightHem_direction/data/Vervet_Sehrinde.h5"
# grid-size of one slice
numX = 28721
numY = 31076
#scan directory for filenames
files = glob.glob(dir + "/*.raw")
numSlices = len(files) # actually 234 slices for this specific dataset
# create hdf5 file
fout = h5py.File(hdf5Filename, 'w')
# create a dataset in the hdf5 file of type unsigned char = uint8
dset = fout.create_dataset("PLI", (numSlices, numX, numY), dtype=np.uint8)
i = 0
for rawFilename in sorted(files):
print "processing " + rawFilename
sys.stdout.flush()
# open each raw file
fin = open(rawFilename, "rb")
# and read the content
v = np.fromfile(fin, dtype=np.uint8, count=numX*numY)
fin.close()
v = v.reshape(1, numX, numY)
# store the data in the hdf5 file at the right place
dset[i, : , :]=v
print "success"
fout.close()
Creating XDMF Files
ParaView needs proper XDMF files to be able to read the data from a hdf5 file. We generated two xdfm files by hand. One for the fullsize dataset, and one for loading a spatial subsampled version via a hyperslab.
The xdmf file for the fullsize dataset is quite simple an defines just the uniform rectilinear grid with one attribute. It is a very good practize to normalize the spatial extend of the grid by setting the grid spacing accordingly. We decided that the grid should have the extend "1.0" in the direction on its largest axis. So the grid spacing is 1.0/31076=3.21792e-5 for the Y- and Z-axis. The X-axis is the direction of the slice cutting, therefore it's grid spacing is larger by a factor of 40, resulting in 40*3.21792e-5=1.2872e-3.
Fullsize Version:
<?xml version ="1.0" ?>
<!DOCTYPE xdmf SYSTEM "Xdmf.dtd" []>
<Xdmf Version="2.0">
<Domain>
<Grid Name="Brain" GridType="Uniform">
<Topology TopologyType="3DCoRectMesh" NumberOfElements="234 28721 31076"/>
<Geometry GeometryType="ORIGIN_DXDYDZ">
<DataItem Dimensions="3" NumberType="Float" Precision="4" Format="XML">
-0.151 -.4621 -0.5
</DataItem>
<DataItem Dimensions="3" NumberType="Float" Precision="4" Format="XML">
1.2872e-3 3.21792e-5 3.21792e-5
</DataItem>
</Geometry>
<Attribute Name="PLI" AttributeType="Scalar" Center="Node">
<DataItem Dimensions="234 28721 31076" NumberType="UChar" Precision="1" Format="HDF">
Vervet_Sehrinde.h5:/PLI
</DataItem>
</Attribute>
</Grid>
</Domain>
</Xdmf>
As the dataset is relatively large (200 GB), we decided to generate a second xdmf file which only reads a subsampled version of the data (every 4th pixel in Y- and Z-direction, 12.5 GB). This can be done via the "hyperslab" construct and adds a little bit more complexity to the description. Please note that the grid spacing has to be adapted to the subsampled grid size accordingly.
Subsampled Version:
<?xml version ="1.0" ?>
<!DOCTYPE xdmf SYSTEM "Xdmf.dtd" []>
<Xdmf Version="2.0">
<Domain>
<Grid Name="Brain" GridType="Uniform">
<Topology TopologyType="3DCoRectMesh" NumberOfElements="234 7180 7760"/>
<Geometry GeometryType="ORIGIN_DXDYDZ">
<DataItem Dimensions="3" NumberType="Float" Precision="4" Format="XML">
-0.151 -0.4626 -0.5
</DataItem>
<DataItem Dimensions="3" NumberType="Float" Precision="4" Format="XML">
1.28866e-3 1.28866e-4 1.28866e-4
</DataItem>
</Geometry>
<Attribute Name="PLI" AttributeType="Scalar" Center="Node">
<DataItem ItemType="Hyperslab" Dimensions="234 7180 7760" NumberType="UChar" Precision="1">
<DataItem Dimensions="3 3" Format="XML">
0 0 0
1 4 4
234 7180 7760
</DataItem>
<DataItem Dimensions="234 28721 31076" NumberType="UChar" Precision="1" Format="HDF">
Vervet_Sehrinde.h5:/PLI
</DataItem>
</DataItem>
</Attribute>
</Grid>
</Domain>
</Xdmf>
Prototyping the movie
Later we will generate the movie by controlling the rendering process in ParaView via a Python-script (pvpython). Before we can do this, we need to find out good camera positions for camera flights, proper color- and transparency-tables, maybe a volume of interest and so on.
To find out the necessary parameters, the data can be loaded with the ParaView GUI first. There one can interactively adjust camera positions, color tables, ..... It is also very helpful to open the Python-Trace window of ParaView, where most parameter changes made in the GUI are shown as Python commands. Those commands can, with little changes, be used in the final Python script for the movie generation.
Generating the movie with a Python script
Attachments (9)
-
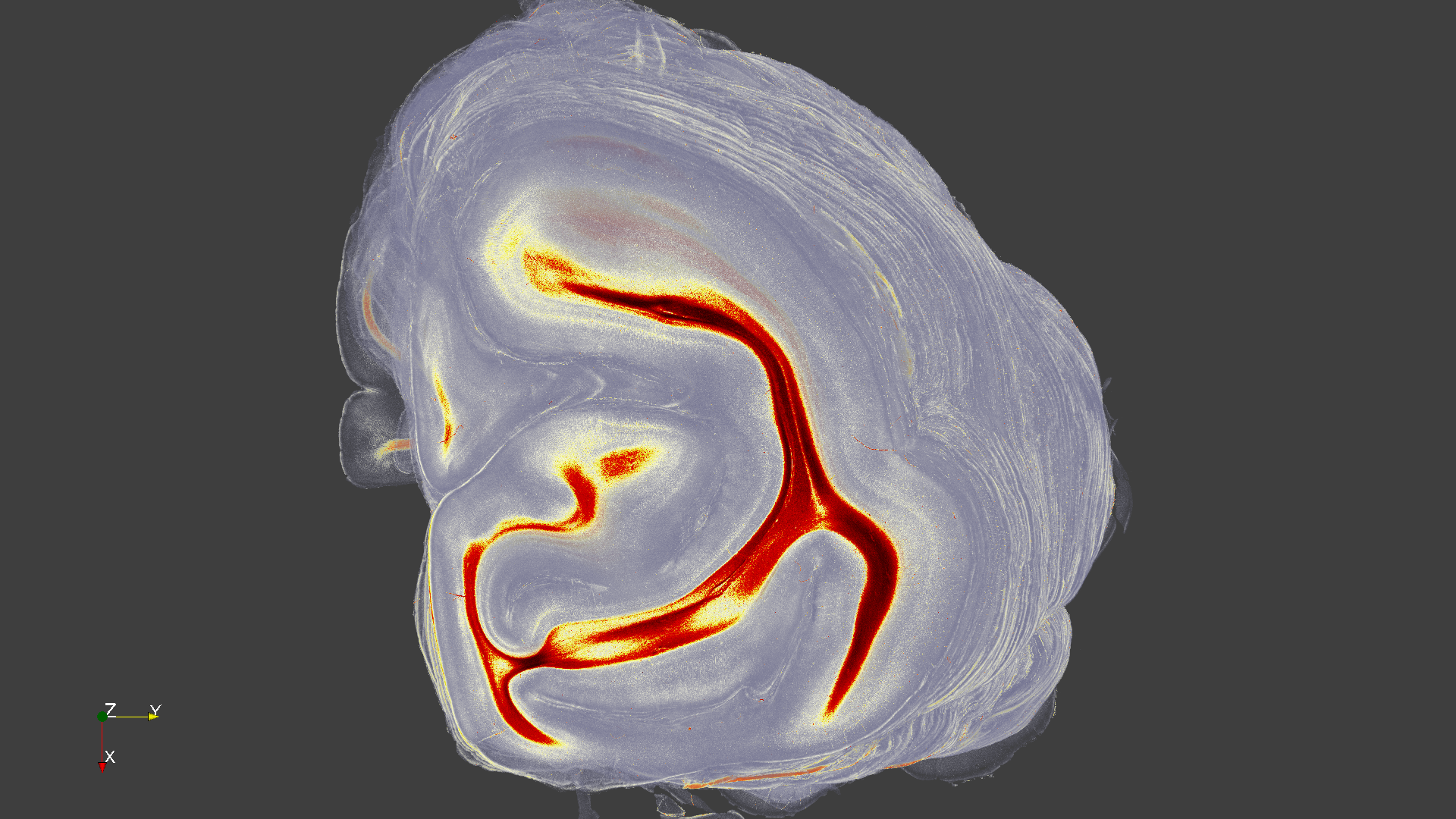
image_0000.png
(1.7 MB
) - added by 7 years ago.
Brain Image
-
orbit.wmv
(1.7 MB
) - added by 7 years ago.
Camera Orbit
-
camera_flight.wmv
(3.2 MB
) - added by 7 years ago.
Camera Flight
-
opacity.wmv
(432.6 KB
) - added by 7 years ago.
Animation of Opacity
-
voi.wmv
(1.2 MB
) - added by 7 years ago.
Animation of Volume of Interest
-
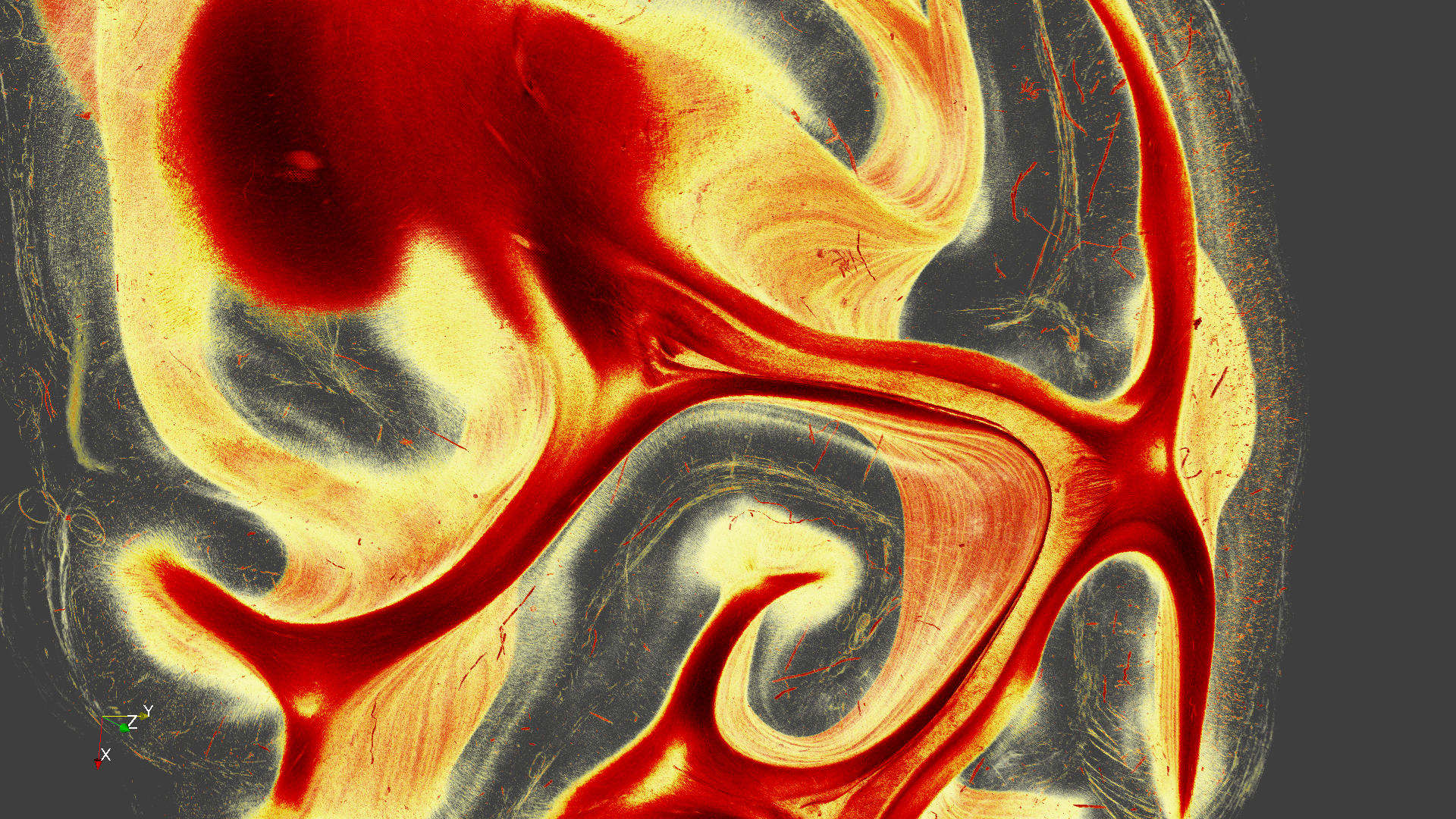
image_0016.png
(1.4 MB
) - added by 7 years ago.
Image_0016
-
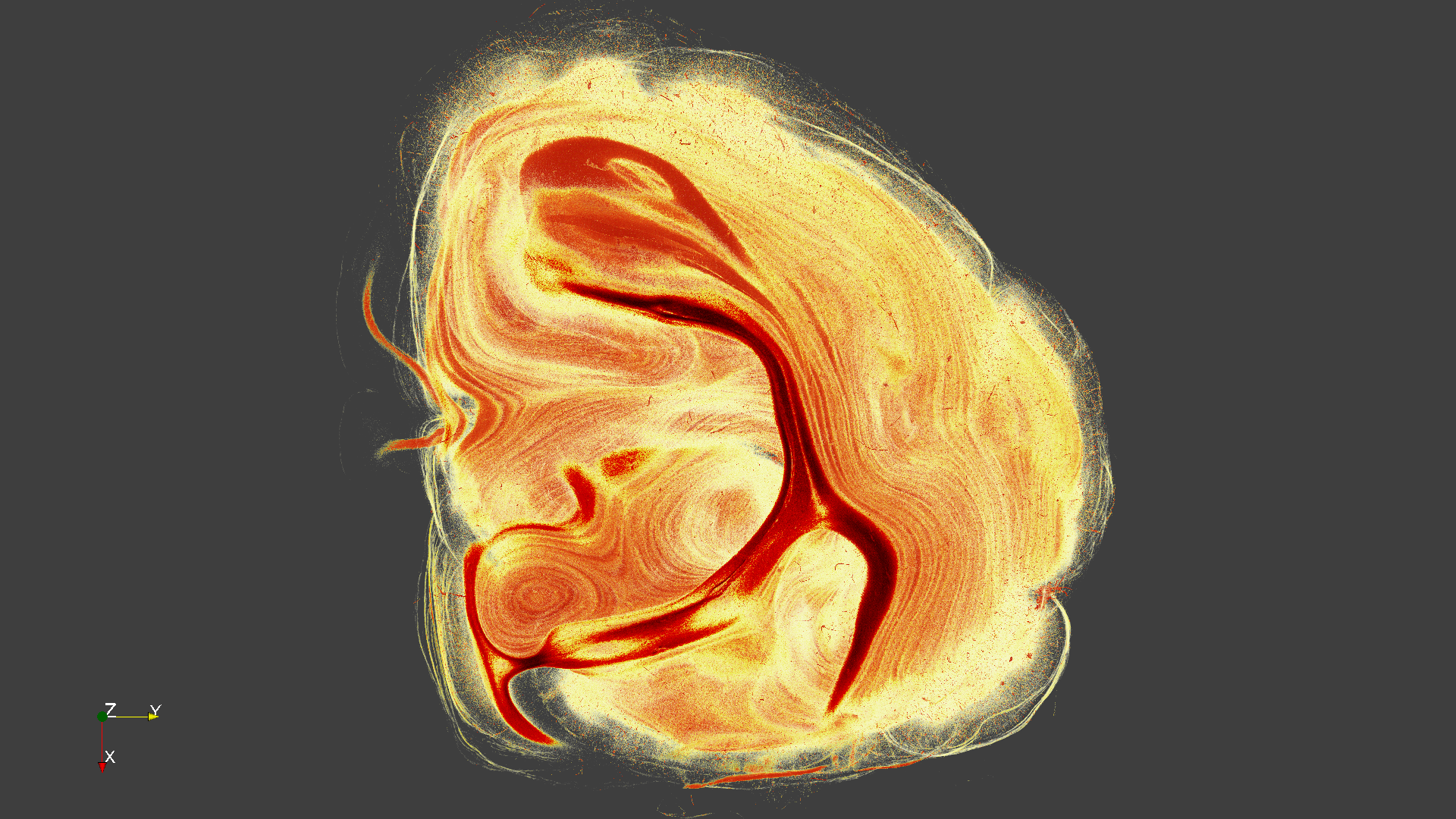
anflug_0140.png
(3.6 MB
) - added by 7 years ago.
Anflug_0140
-
image_0128.png
(1.9 MB
) - added by 7 years ago.
Image_0128
-
image_0210.png
(1.5 MB
) - added by 7 years ago.
Image_210
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
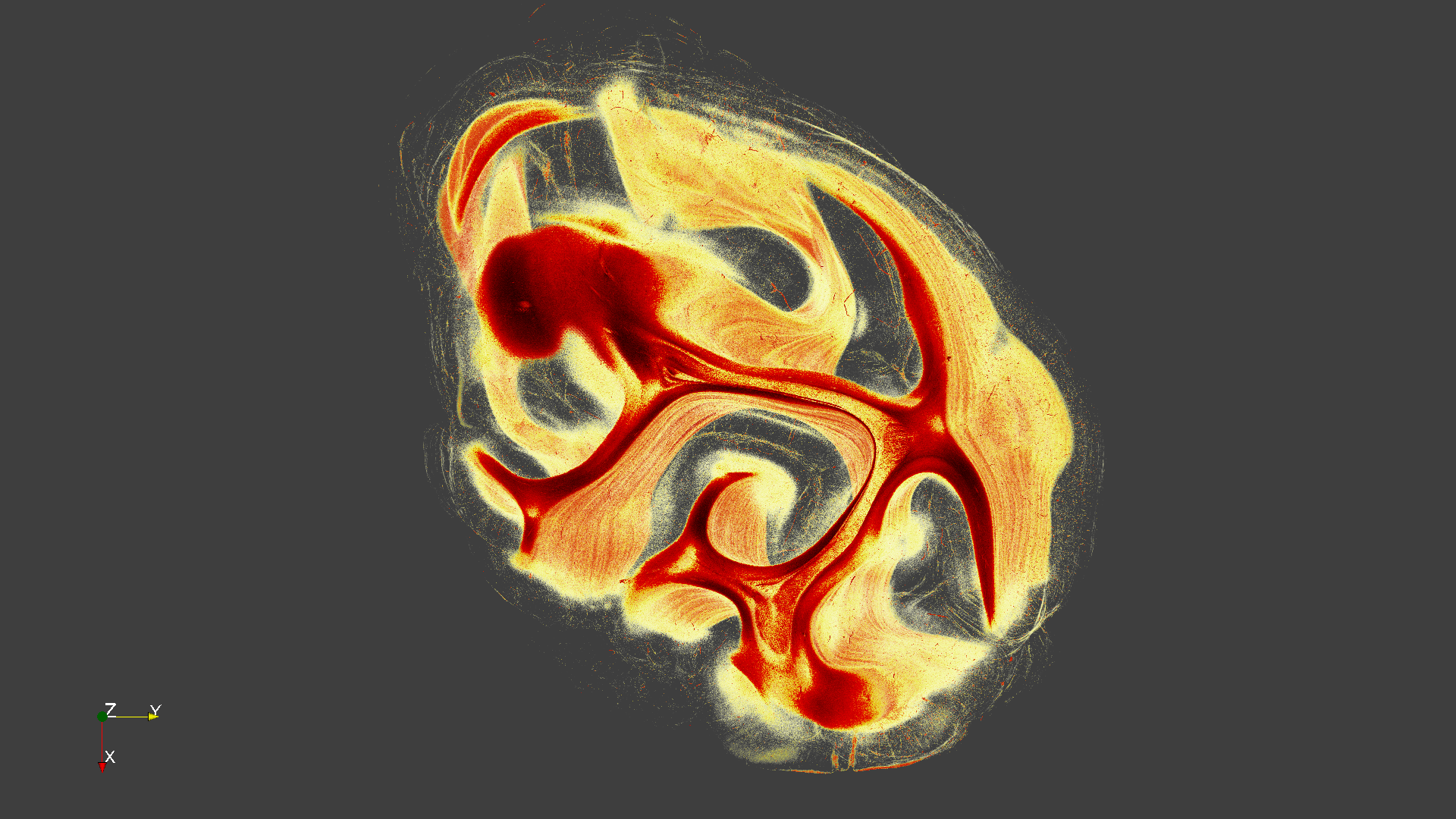{kind=link}