| Version 1 (modified by , 7 years ago) ( diff ) |
|---|
Animated movie of neuroscience brain data with ParaView
Background
At FZJ, the institute for structural and functional organisation of the brain (INM-1) develops a 3-D model of the human brain which considers cortical architecture, connectivity, genetics and function. The INM-1 research group Fiber Architecture develops techniques to reconstruct the three-dimensional nerve fiber architecture in mouse, rat, monkey, and human brains at microscopic resolution. As a key technology, the neuroimaging technique Three-dimensional Polarized Light Imaging (3D-PLI) is used. To determine the spatial orientations of the nerve fibers, a fixated and frozen postmortem brain is cut with a cryotome into histological sections (≤ 70 µm). Every slice is then scanned by high resolution microscopes.
Data
The datset used in this visualisation scenario consists of 234 slices of gridsize 31076x28721, resulting in a rectilinear uniform grid of size 31076x28721x234, ~200 GB memory usage in total. The data was stored as raw binary unsigned char data, one file for each slice.
Conversion to HDF5
Because ParaView has a very decent XDMF/HDF5 reader, we decided to convert the raw data to hdf5 first. This was done using a Python script. Before Python can be used on our JURECA cluster, the necessary modules have to be loaded first:
module load GCC/5.4.0 module load ParaStationMPI/5.1.5-1 module load h5py/2.6.0-Python-2.7.12 module load HDF5/1.8.17
In the Python-script, the directory containing the 234 slice files is scanned for the filenames. Every file is opened and the raw content is read into a numpy array. This numpy array is written into a hdf5 file, which was created first.
import sys
import h5py # http://www.h5py.org/
import numpy as np
import glob
dir = "/homeb/zam/zilken/JURECA/projekte/hdf5_inm_converter/Vervet_Sehrinde_rightHem_direction/data"
hdf5Filename="/homeb/zam/zilken/JURECA/projekte/hdf5_inm_converter/Vervet_Sehrinde_rightHem_direction/data/Vervet_Sehrinde.h5"
# grid-size of one slice
numX = 28721
numY = 31076
#scan directory for filenames
files = glob.glob(dir + "/*.raw")
numSlices = len(files) # actually 234 slices for this specific dataset
# create hdf5 file
fout = h5py.File(hdf5Filename, 'w')
# create a dataset in the hdf5 file of type unsigned char = uint8
dset = fout.create_dataset("PLI", (numSlices, numX, numY), dtype=np.uint8)
i = 0
for rawFilename in sorted(files):
print "processing " + rawFilename
sys.stdout.flush()
# open each raw file
fin = open(rawFilename, "rb")
# and read the content
v = np.fromfile(fin, dtype=np.uint8, count=numX*numY)
fin.close()
v = v.reshape(1, numX, numY)
# store the data in the hdf5 file at the right place
dset[i, : , :]=v
print "success"
fout.close()
Creating XDMF Files
Attachments (9)
-
image_0000.png
(1.7 MB
) - added by 7 years ago.
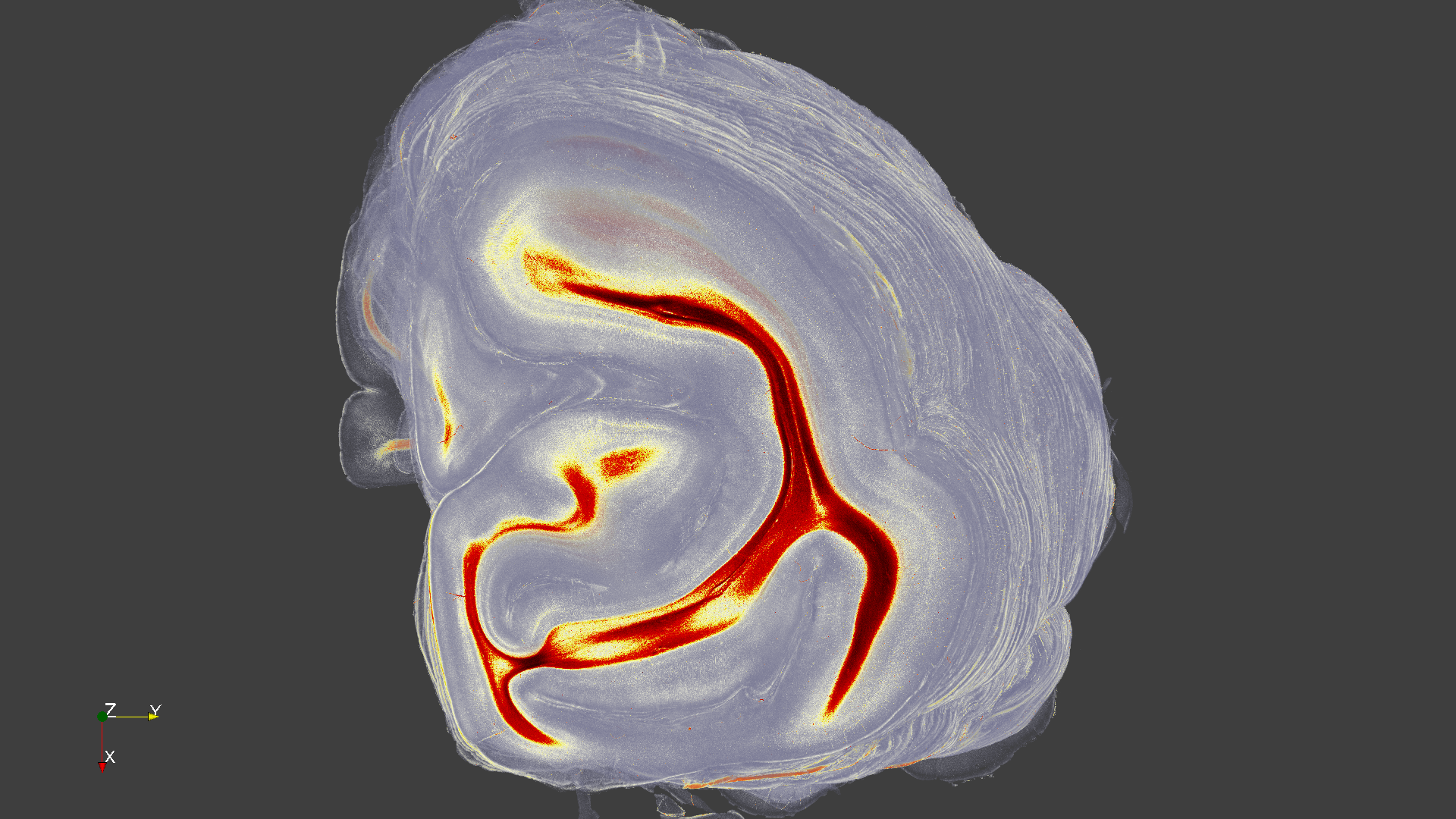
Brain Image
-
orbit.wmv
(1.7 MB
) - added by 7 years ago.
Camera Orbit
-
camera_flight.wmv
(3.2 MB
) - added by 7 years ago.
Camera Flight
-
opacity.wmv
(432.6 KB
) - added by 7 years ago.
Animation of Opacity
-
voi.wmv
(1.2 MB
) - added by 7 years ago.
Animation of Volume of Interest
-
image_0016.png
(1.4 MB
) - added by 7 years ago.
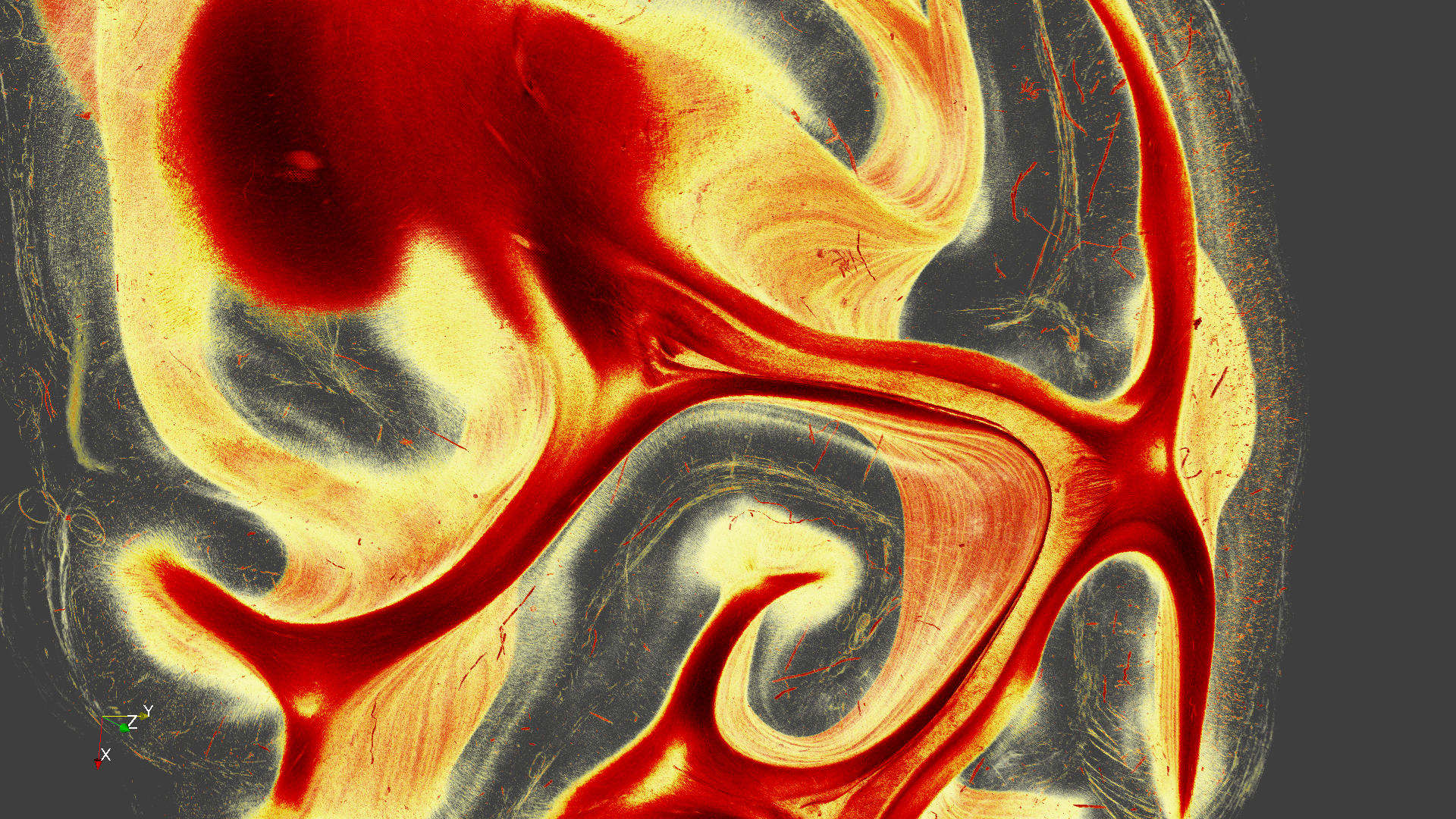
Image_0016
-
anflug_0140.png
(3.6 MB
) - added by 7 years ago.
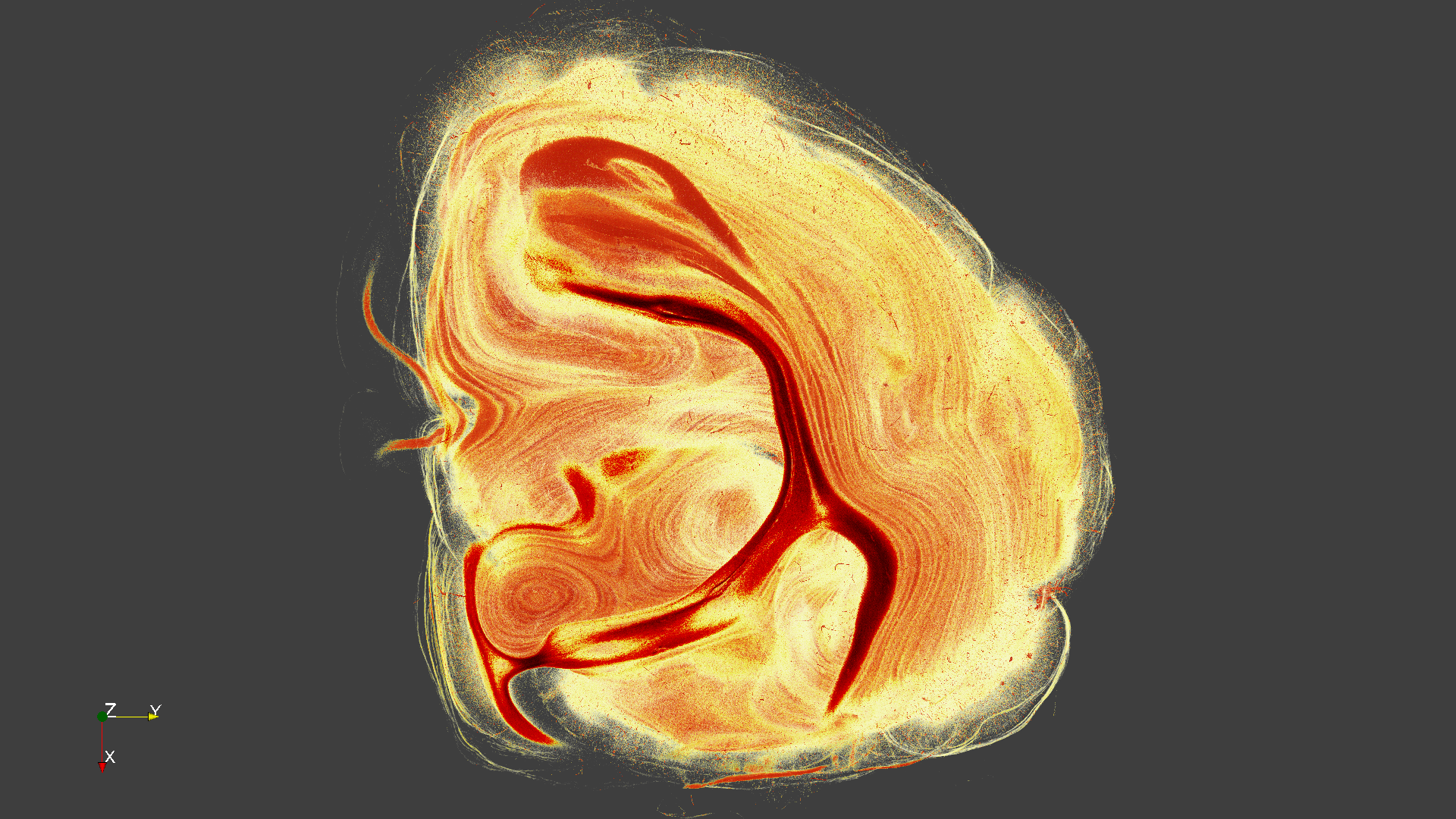
Anflug_0140
-
image_0128.png
(1.9 MB
) - added by 7 years ago.
Image_0128
-
image_0210.png
(1.5 MB
) - added by 7 years ago.
Image_210
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
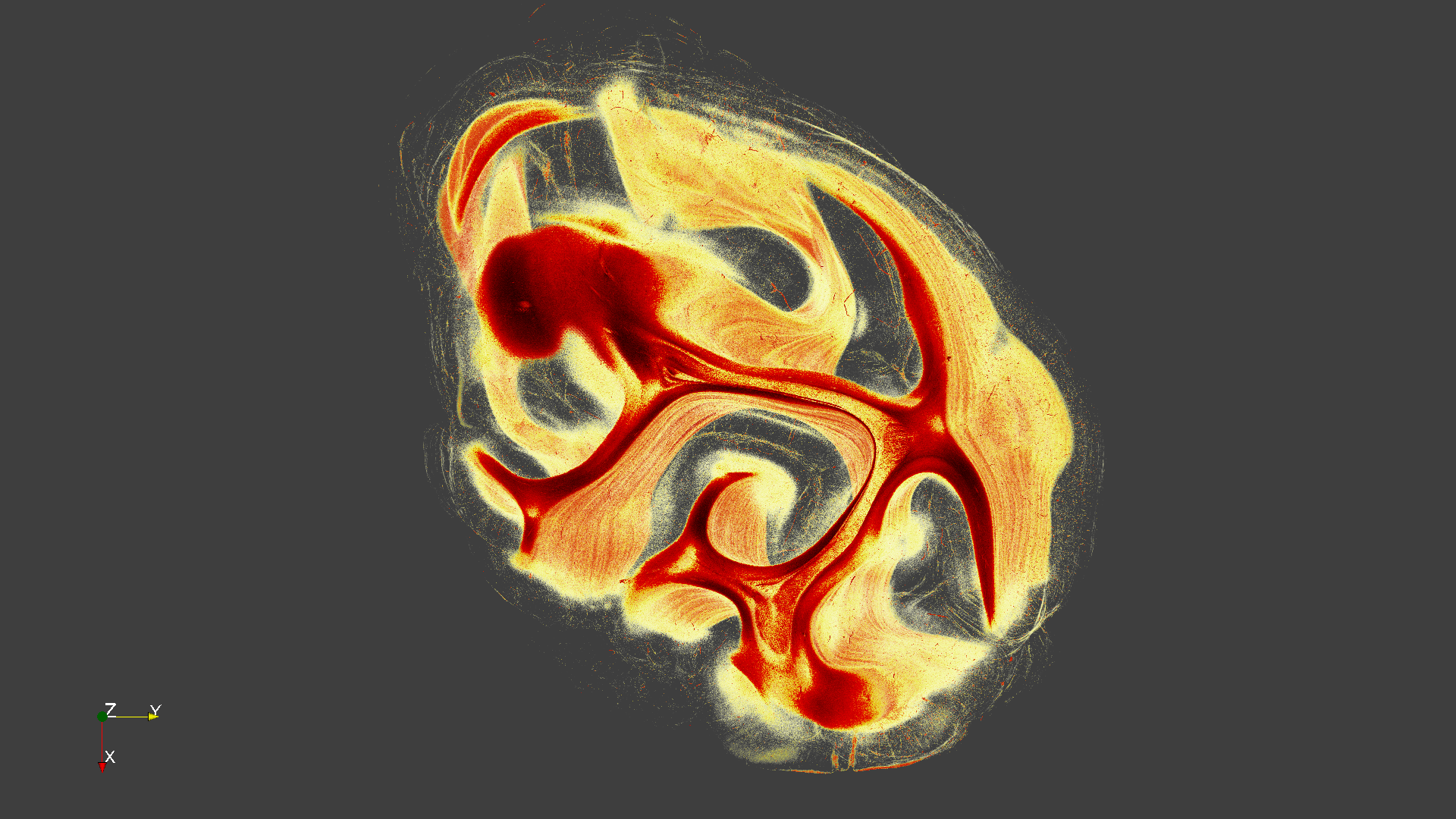{kind=link}